Every inference feeds the cycle
Instrument in minutes
Add the zero-dependency Wild Edge SDK. No changes to inference code.
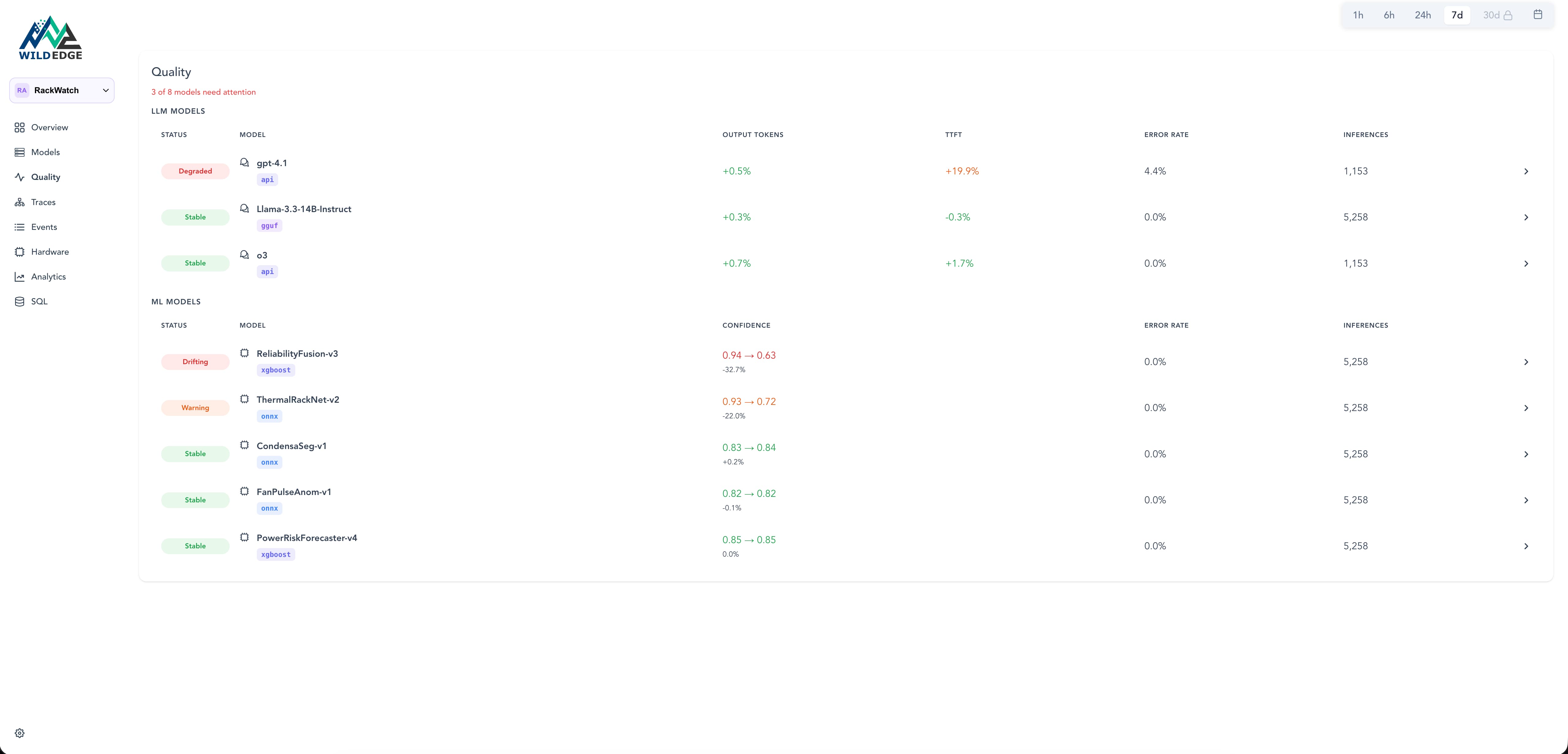
Model performance in one place
Detect drift, latency degradation, and confidence shifts across all models before a support ticket lands.
Deep inference analytics
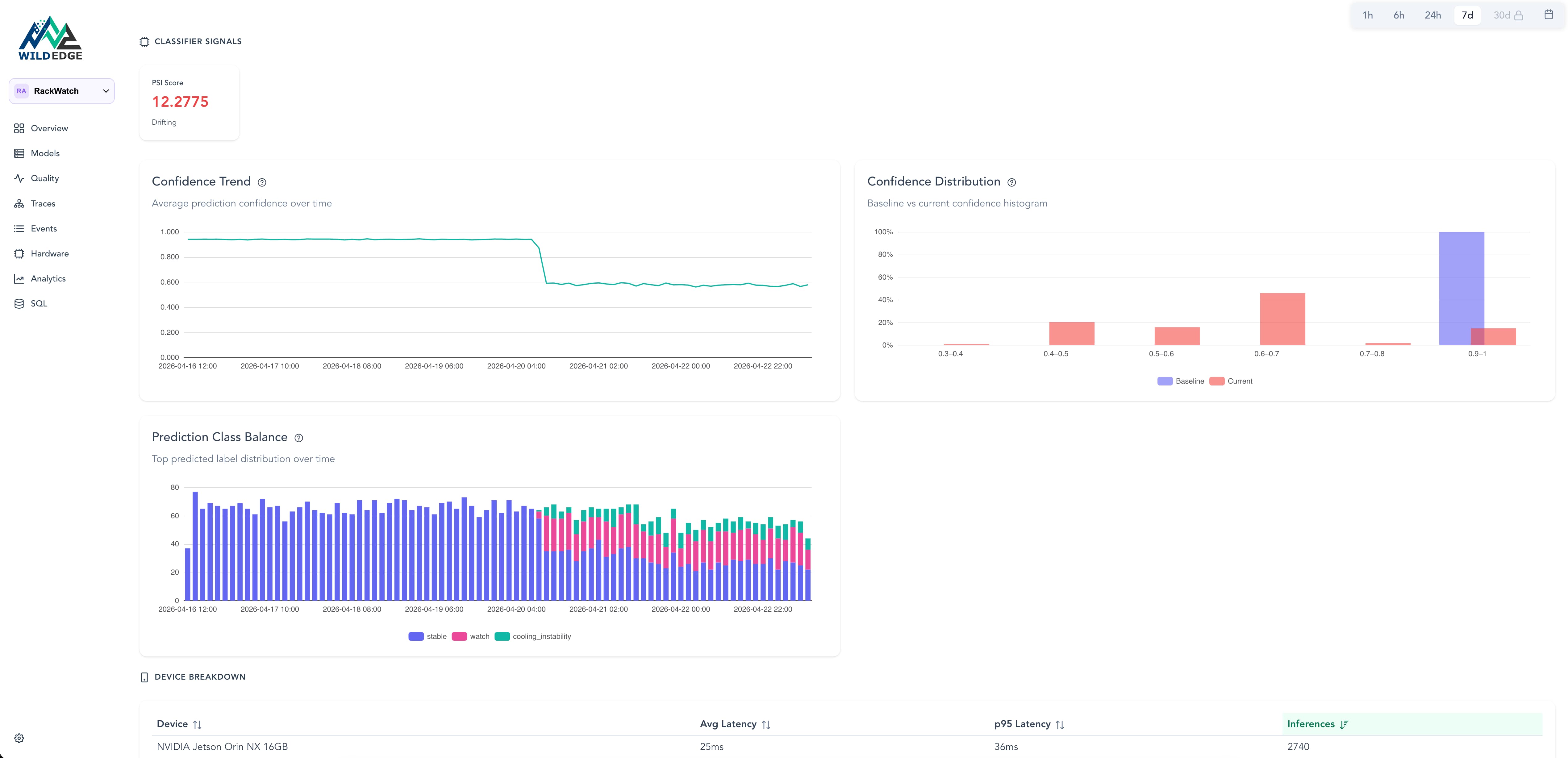
Latency, error rate, and drift broken down by device, OS, accelerator, and thermal state.

Agentic traces and reasoning chains
Every step of agentic pipelines: timing, tokens, cache hits, tool call sequences.
Build datasets from production
Filter production events by confidence, device, or outcome. Attach inputs. Build a dataset from real failures and user feedback.
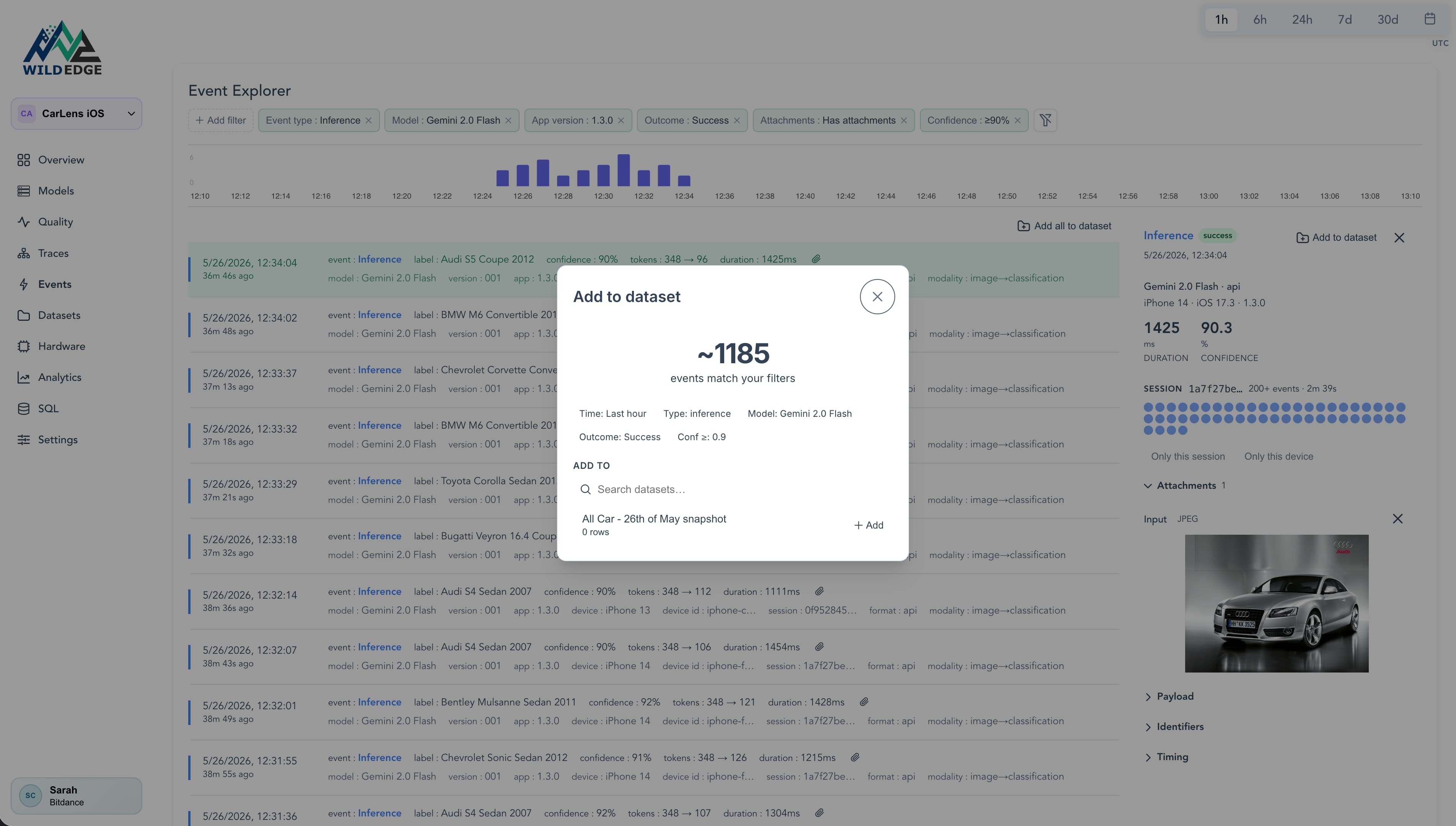
Confidence-based event filtering
Slice production events by model confidence, device type, or outcome to seed your dataset.
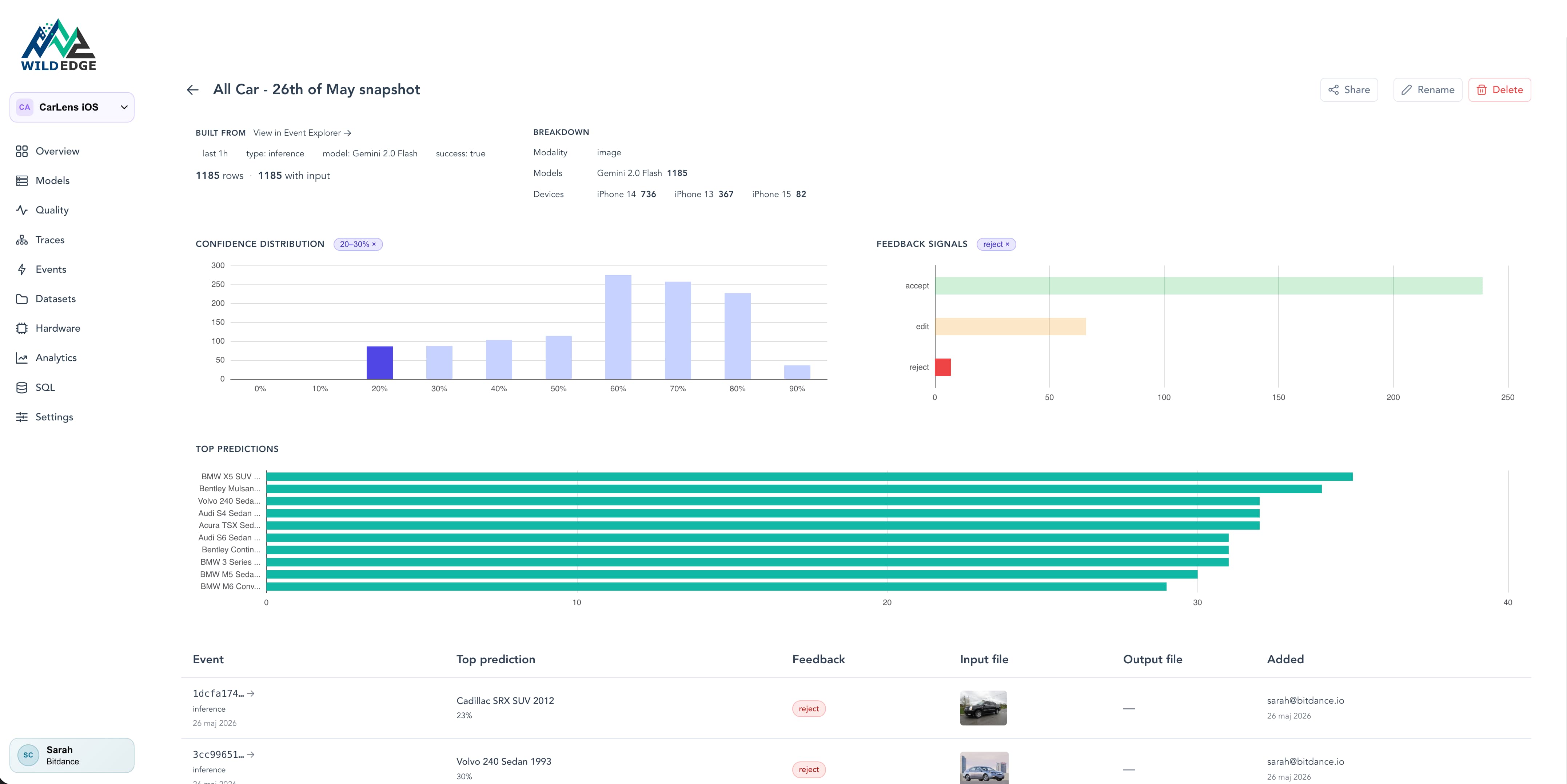
Dataset quality and coverage
Confidence distribution and user corrections surface where the model is weakest.
The data is yours
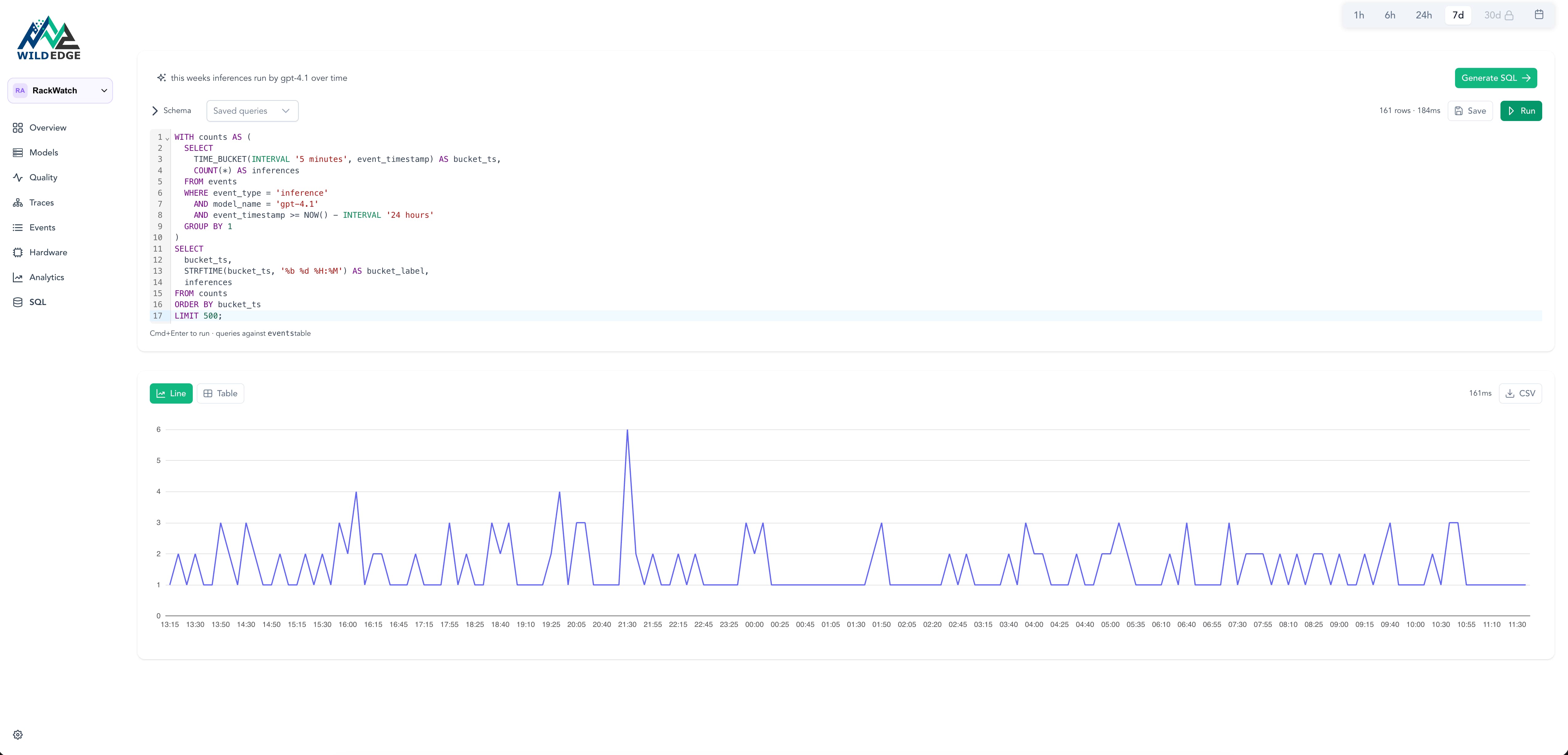
Query the full inference history in plain language or SQL. Filter by hardware, model version, confidence score, or any field captured at inference time.